The synonyms of 'good' are:
['adept', 'beneficial', 'commodity', 'dear', 'dependable', 'effective', 'estimable', 'expert', 'full', 'honest', 'honorable', 'in_effect', 'in_force', 'just', 'near', 'practiced', 'proficient', 'respectable', 'right', 'ripe', 'safe', 'salutary', 'secure', 'serious', 'skilful', 'skillful', 'sound', 'soundly', 'thoroughly', 'undecomposed', 'unspoiled', 'unspoilt', 'upright', 'well']
The antonyms of 'good' are:
['bad', 'badness', 'evil', 'evilness', 'ill']
# https://www.nltk.org/howto/wordnet.html
# synset1.path_similarity(synset2):
# Return a score denoting how similar two word senses are, based on the shortest path that
# connects the senses in the is-a (hypernym/hypnoym) taxonomy.
# The score is in the range 0 to 1.
# synset1.lch_similarity(synset2):
# Leacock-Chodorow Similarity: Return a score denoting how similar two word senses are,
# based on the shortest path that connects the senses (as above)
# and the maximum depth of the taxonomy in which the senses occur. The relationship is given
# as -log(p/2d) where p is the shortest path length and d the taxonomy depth.
# synset1.wup_similarity(synset2):
# Wu-Palmer Similarity: Return a score denoting how
# similar two word senses are, based on the depth of the two senses in the taxonomy and
# that of their Least Common Subsumer (most specific ancestor node).
w1='good'
w2='dear'
w3='bad'
w1s=wn.synsets(w1)[0]
w2s=wn.synsets(w2)[0]
w3s=wn.synsets(w3)[0]
print("The path similarity between %s and %s is %s" %(w1,w2,w1s.path_similarity(w2s)))
print("The path similarity between %s and %s is %s \n" %(w1,w3,w1s.path_similarity(w3s)))
print("The lch similarity between %s and %s is %s" %(w1,w2,w1s.lch_similarity(w2s)))
print("The lch similarity between %s and %s is %s \n" %(w1,w3,w1s.lch_similarity(w3s)))
print("The wup similarity between %s and %s is %s" %(w1,w2,w1s.wup_similarity(w2s)))
print("The wup similarity between %s and %s is %s" %(w1,w3,w1s.wup_similarity(w3s)))
The path similarity between good and dear is 0.08333333333333333
The path similarity between good and bad is 0.2
The lch similarity between good and dear is 1.1526795099383855
The lch similarity between good and bad is 2.0281482472922856
The wup similarity between good and dear is 0.15384615384615385
The wup similarity between good and bad is 0.6666666666666666
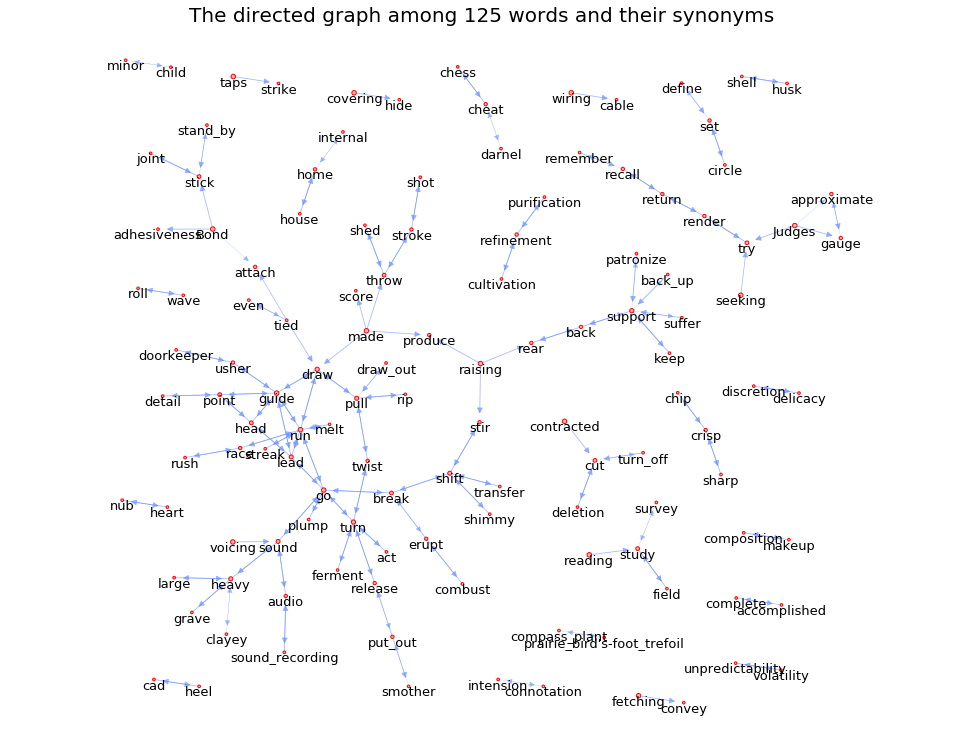
The graph among 125 words and their synonyms has 125 nodes and 195 edges
The graph among 125 words and their synonyms is a directed graph
The graph among 125 words and their synonyms graph is a weighted graph
The graph among 125 words and their synonyms graph is not strongly connected and it has 45 strongly connected components
The largest strongly connected component of this graph has 39 nodes and 88 edges
The graph among 125 words and their synonyms graph is not weakly connected and it has 24 weakly connected components
The largest weakly connected component of this graph has 63 nodes and 125 edges
The density of the graph among 125 words and their synonyms is 0.013
The transitivity of the graph among 125 words and their synonyms is 0.107
The reciprocity of the graph among 125 words and their synonyms is 0.882
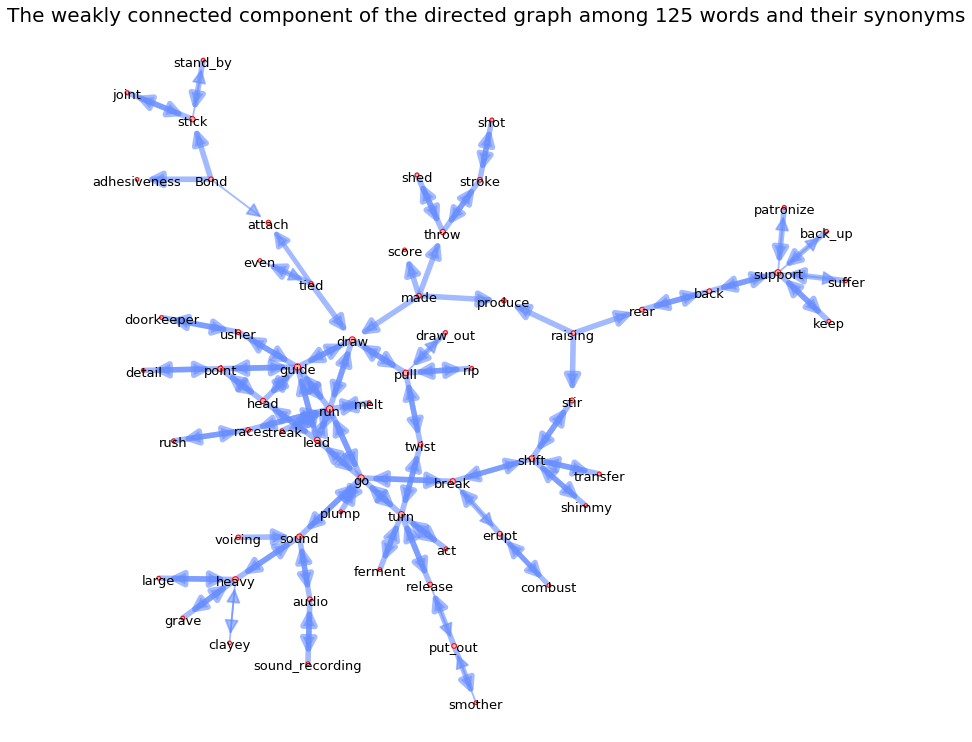
The weakly connected component of the directed graph among 125 words and their synonyms has 63 nodes and 125 edges
The weakly connected component of the directed graph among 125 words and their synonyms is a directed graph
The weakly connected component of the directed graph among 125 words and their synonyms graph is a weighted graph
The weakly connected component of the directed graph among 125 words and their synonyms graph is not strongly connected and it has 13 strongly connected components
The largest strongly connected component of this graph has 39 nodes and 88 edges
The weakly connected component of the directed graph among 125 words and their synonyms is a weakly connected graph
The density of the weakly connected component of the directed graph among 125 words and their synonyms is 0.032
The transitivity of the weakly connected component of the directed graph among 125 words and their synonyms is 0.110
The reciprocity of the weakly connected component of the directed graph among 125 words and their synonyms is 0.896
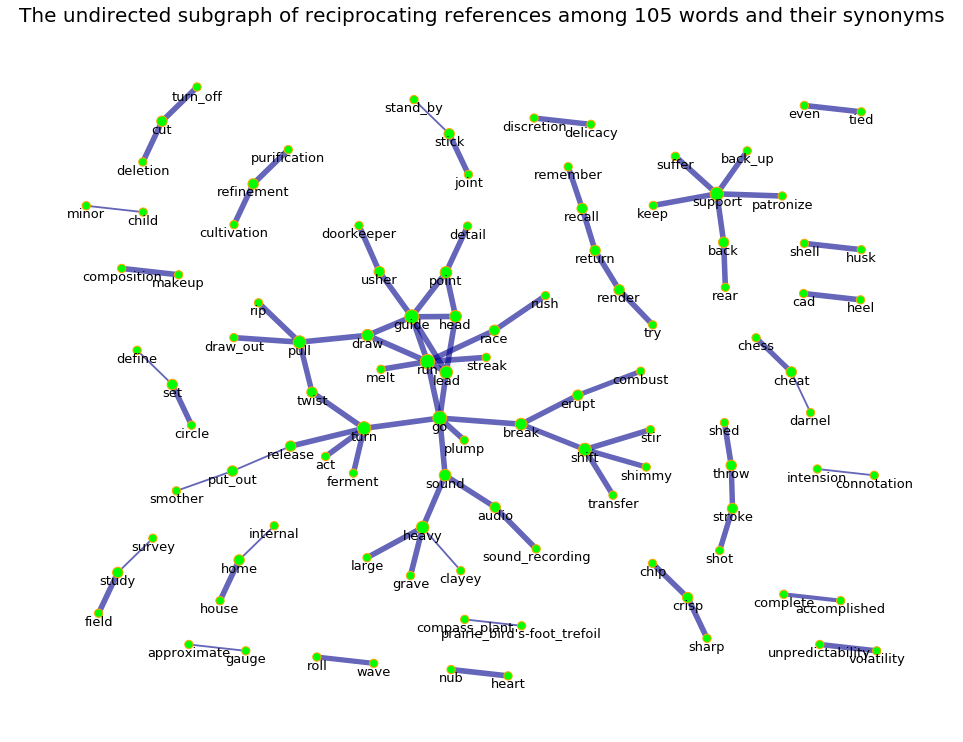
The subgraph of reciprocating references among 105 words and their synonyms has 105 nodes and 86 edges
The subgraph of reciprocating references among 105 words and their synonyms is an undirected graph
The subgraph of reciprocating references among 105 words and their synonyms graph is a weighted graph
The subgraph of reciprocating references among 105 words and their synonyms graph is a disconnected graph and it has 25 connected components
The largest connected component of this graph has 39 nodes and 44 edges
The density of the subgraph of reciprocating references among 105 words and their synonyms is 0.016
The transitivity of the subgraph of reciprocating references among 105 words and their synonyms is 0.115
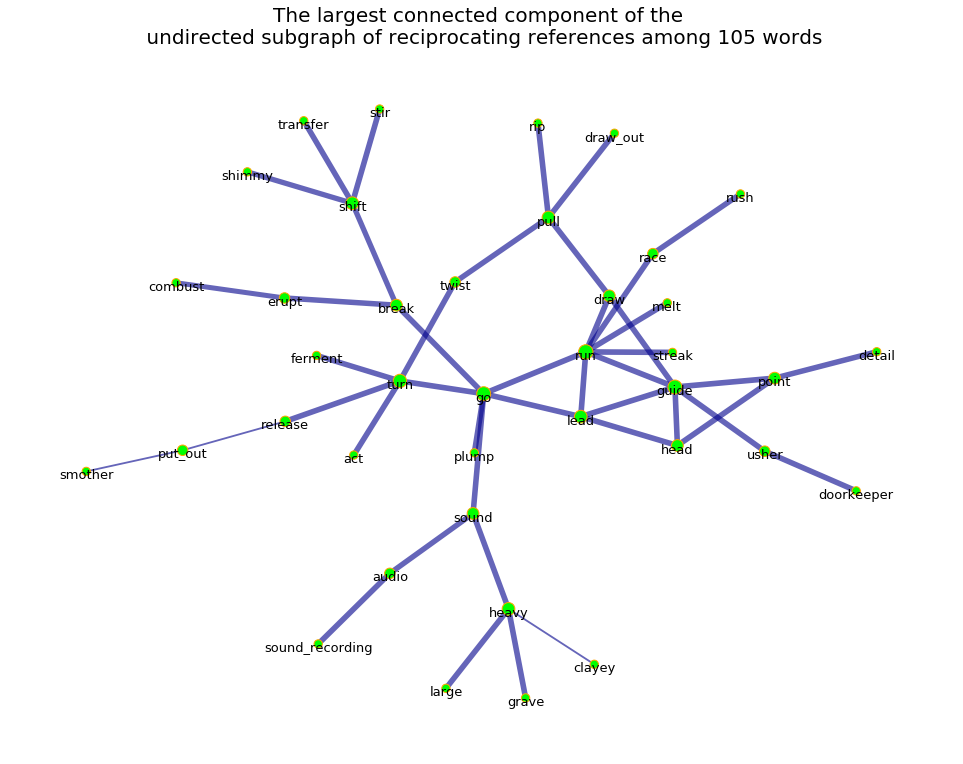
The largest connected component of the undirected subgraph of reciprocating references among 105 words and their synonyms has 39 nodes and 44 edges
The largest connected component of the undirected subgraph of reciprocating references among 105 words and their synonyms is an undirected graph
The largest connected component of the undirected subgraph of reciprocating references among 105 words and their synonyms graph is a weighted graph
The largest connected component of the undirected subgraph of reciprocating references among 105 words and their synonyms is a connected graph
The density of the largest connected component of the undirected subgraph of reciprocating references among 105 words and their synonyms is 0.059
The transitivity of the largest connected component of the undirected subgraph of reciprocating references among 105 words and their synonyms is 0.140